
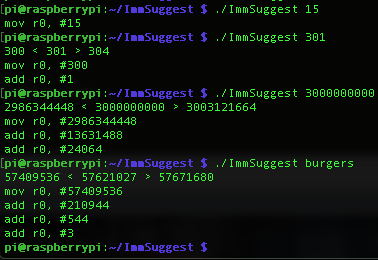
Encoding 12 bit immediate values for 32 bit ARM instructions can get somewhat complicated when the numbers get large enough, click this article for more details.
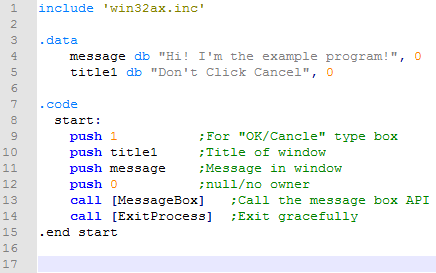
Invoke is a common calling convention for assembly source, especially as found as examples on the internet. But 'invoke' isn't assembly, it's abstracted, and it makes disassembly harder to follow. This post is a discussion of this issue and how I came to using the standard assembly 'call' convention.

RRX is encoded as ROR with the imm5 field hardcoded as 0's.
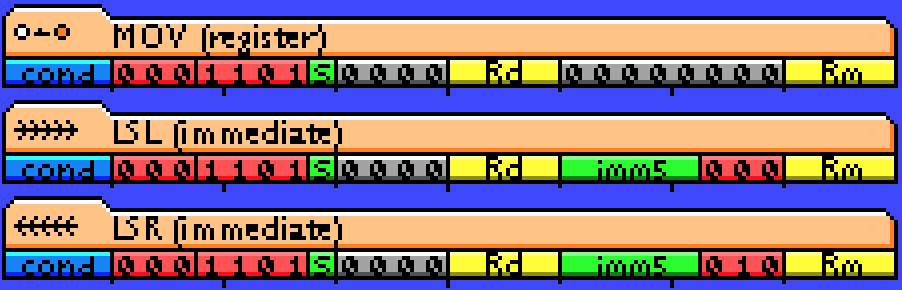
The MOV and shift instructions (like LSL) are encoded the same. You could use the LSL instruction with the imm5 field hardcoded to 0's and it will encode exactly the same as MOV.
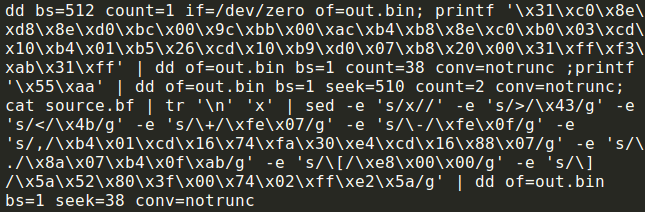
Building a BrainFuck compiler with the main component being the sed tool.

The order of adding two registers in a pointer shouldn't matter logically, but it does when it comes to encoding. This is because the 2nd register is a multiplier even if only be 1. Read more for the interesting details.
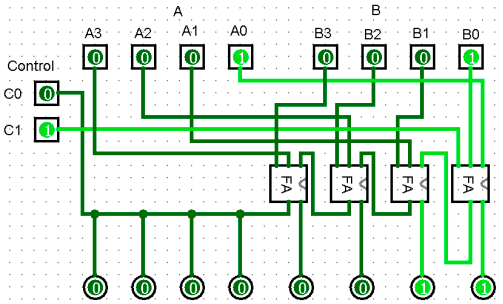
An exploration of some ambiguities that signed numbers can introduce to your assembler, what your assembler will choose, and how you can choose anything you want.
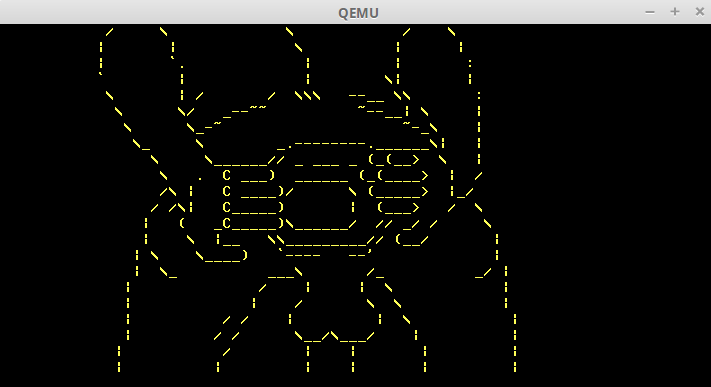
A quickstart guide to making some boot sector games. This guide assumes you know some x86 basics. From there, you learn how to boot a skeleton with a stack, video memory, keyboard control, timing loops, colors, and random.

These are the slides (with slide notes) that I gave at Cactus Con in 2016. It's about my unrealized childhood dream of programming in machine code directly (unrealized as a child).

Abuse of the REP prefix for instructions that it doesn't apply to.