
While reading through the epic page-turning Intel Manual, I found something interesting in the SSE2 section (chapter 11 of Volume 1):
I find little nuggets like this very interesting. What this tells me is that there is a feature that can be used in binary executable code that I am not allowed to explicitly use in Assembly Language (or any higher-level language for that matter). This is not to say that an assembly or compiler wont do this for you when seen fit, but I’m the programmer; if I wanted everything done for me, I wouldn’t be the programmer. I understand that a compiler does a lot of tedious stuff for me that I wouldn’t want to do on a regular basis, that is ok. What is less ok is having the option taken away from me.
I should also say that under normal conditions, a branch hint (and the SSE feature set) would not normally interest me. As I will get to later, this branch hint feature is hard for me to make useful. The actual reason I’m interested in this feature is because I was told I can’t. so let’s can.
Below will be some assembly (nasm syntax) code. It is a simple program. It takes a file through standard in. For each byte, it decides if it is below a certain threshold (in this case the value of 0xFD), if it is, it prints the character Y to standard out, otherwise, it prints the letter X. I attempted to put somewhat liberal commenting in:
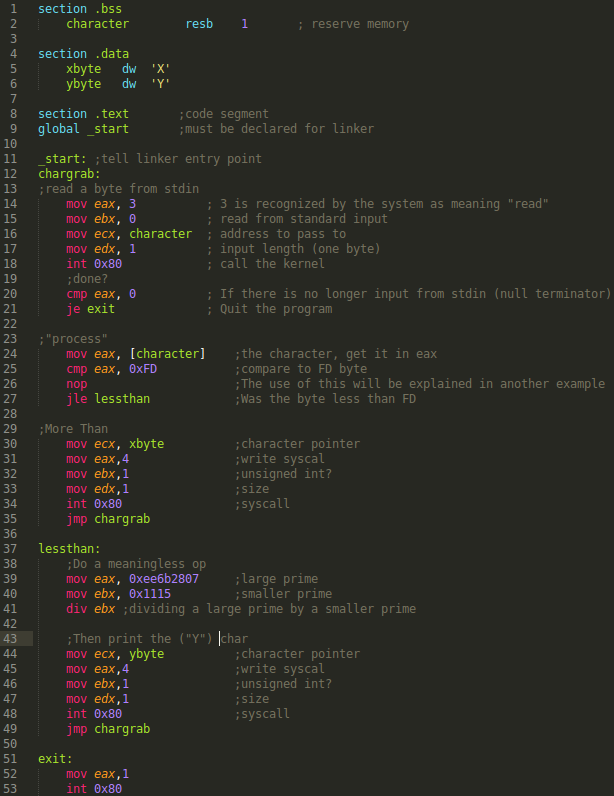
So I’m going to assemble this:
![]()
We should probably also get some random data to feed into this program:

No let’s run our program feeding in this file we created:
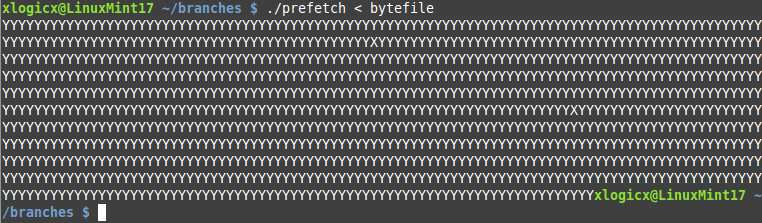
You’ll notice (maybe) that this was mostly Y’s printed, but if you look closely, there are a couple of X’s. I counted at least 2 of them before my eyes started bleeding.
Great, so our normal program works, what do these branch hints have to do with anything. To digress into that briefly: RAM is slower than processor cache. executable code comes from RAM (but can get cached). When an executable program hits a fork in the road (conditional jump), it would make sense for the processor to cache the most likely path it will take. This is what a branch hint does for us. We have 2 options: “branch taken” and “branch not taken,” of which refers to and precedes the conditional jump that it is referring to. We can try and argue “compiler knows best,” but if a conditional jump depends on external data (as my sample program does), which is not an uncommon scenario, it is me that understands the data, not the compiler.
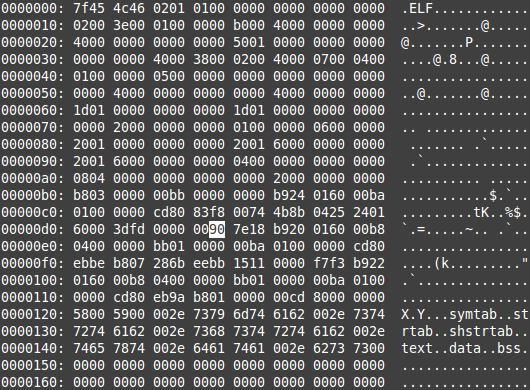
I will highlight the section of code we want to try this with in a debugger (Evans Debugger):
![]()
We can see the particular part of our above code where we compare the current byte with 0xFD, then do nothing real quick (nop), and then conditionally jump to the code at 0x4000f2 if the byte is less than (we are currently at instructions 0x4000d2-0x4000d8).
So since we know the branch taken and not taken machine bytes are 0x3e and 0x2e (respectively), let’s just patch the nop we strategically placed in there. It’s just a byte-for-byte replacement that doesn’t affect our code/file size. Use a hex editor of your choice to modify the below highlighted byte to a 3e/2e
You end up with:
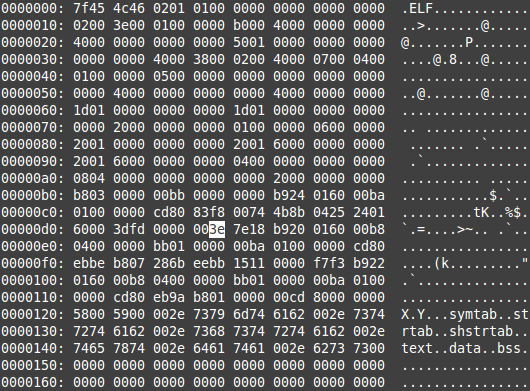
Let’s see this in the debugger again:
![]()
Notice how this is exactly the same machine code as the above debugger output with exception to the 0x90 now being a 0x3e. More importantly, notice how it arranged the instructions; instead of being 3 distinct instructions, there are 2. We have the same cmp instruction, and a similar jle instruction, but now prefixed with our 0x3e “branch taken” branch hint prefix.
This program appears to run nearly identical to the unpatched one. In fact, it does run logically identically to it. What we expect to see is a difference in timing. But likely not for a program as brief as this one.
Because of this, I did testing on variations of this program.
Considering the above, I ran 54 different versions of this program, and timed them all with /usr/bin/time. I ran each of these 54 tests 5 times (to reduce anomalies/outliers). If this sounds time consuming, it’s ok; I have aspergers. Some of these finished in 2-5 minutes, and some of them took up to 25 minutes. The time differences had a lot less to do with the branch hints however (obviously a 1MB input is going to run shorter than a 50MB one).
So how much of a difference did the branch hint make in my above tests. For a 25 minute run, I was able to shave off about 3-5 seconds…consistently. Underwhelming. It’s possible that I just needed to test this differently. However, it wasn’t the point for me to come up with an awesome speed hack optimization for people. No, I’m a hacker, I did this because I wasn’t supposed to be able to, and did it anyway. Also, to demonstrate one of the many ways you can do stuff in machine code that you can’t do in Assembly; this will not be the only post in the series of “Assembly Is Too High-Level,” just the first.
Edit:
In talking with Altf4 at a 2600 meeting, he found that this feature may have been deprecated a long time ago. If true, this would explain a lot. However, I still did notice a consistent timing difference with the branch hint, but this could be more explained that I am actually removing a nop and replacing it with something that is part of the next instruction; effectively marginally lessening the run time.