I've been making a few posts on how I find situations where assembly language would be too high-level, almost to the point of evangelizing it. However, I realized that I have not yet gone into any kind of explanation on exactly what tricks I am using to directly code in machine code. There are actually a few ways this can be done. I will explain 2 of them. There are pros and cons to each.
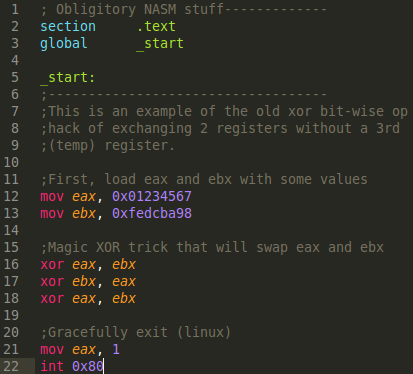
Instead of using the same old tired shellcode example I use for other PoC's, I'm going to use something different. This is also for practical purposes as well; the shellcode examples require self-modifying code (.text section in ELF needs to be rwx), I figured this would needlessly complicate this post. Instead, I demonstrate an old small yet amazing trick. The trick is to exchange the data of 2 registers without a 3rd temporary register (or even temporary memory usage). Obviously, I wont cheat with the xchg opcode. You can do this with 3 strategic XOR operations. Here is the asm source demoing this:
Know that eax will have 01234567 and ebx will have fedcba98. Below is a screenshot of a debugger just after the 3rd xor, note that the registers are swapped at this point:

To dispel some confusion, the leading f's on the 2nd instruction can effectively be ignored. We are seeing this because I am running this on a 64-bit machine, so it is showing as a sign-extended value if the value was to be interpreted as a negative signed integer (2's compliment). Negative values with 'signed' data is anything above and including 0x80..... It is completely irrelevant for this demo and you can pretend the f's aren't even there and it still works the same.
So we see assembly that closely resembles our source file in the debugger. What we want to program with is what we see directly to the left of it. We want to write '31 d8' instead of xor eax, ebx.
This is my preferred method. I will first mention two downsides I can think of for this method. The first major downside is that this tool only knows how to make 32-bit ELF executables. They will run just fine on a 64-bit computer, it's just that you can't experiment with 64-bit machine code. The other minor downside is that this is a script that you have to download (not standard in a distro nor part of popular package managers). You can find it here: m2elf. Although, there should not be any crazy dependencies, I made sure of that. This script is also included in the newest version of remnux (v6), so if you want a full environment out of the box, Remnux v6 comes with m2elf, nasm, and edb all ready to go.
The upside to this tool is that it is very easy to program with. The bytes you enter are literally how the machine code will look in the executable (and debugger). This is not actually the case for Method 2, because of Intels awesome Little-Endianness. Source files for m2elf can just be pure ASCII-hex bytes, or have comments if you so choose. Here's what the m2elf source looks like for our xchg'ing program:
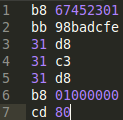
The spacing between bytes and returns were added by me (for clarity), but you can have it all on one line if you really wanted to, whitespace isn't interpreted. I explicitly entered returns for each instruction, and used a space between the operation and the operand. Below are the commands you need to enter in order to 'assemble' and allow for execution:
![]()
swap.m was the input source file, and 'swapm' is the file we can then run/execute. But before we do that, we have to make it executable (because I didn't handle that with m2elf directly). You may not need to do '744' exactly for the permissions, just make sure it is executable if you don't prefer '744', but 744 does work fine. (UPDATE: The latest version of m2elf does not require the chmod step, it defaults to '755' now)
You can now execute swapm like any other program, and step through it in edb. On a side-note, if you want the code to be self-modifying, the argument to m2elf is --writeover. Also, note that the entry point is 0x08000060, this is something you can always count on for m2elf. So this makes it very accessible to experiment with self-modifying code techniques.
In the context of writing machine code, NASM directives allow us to directly enter bytes anywhere we want interspersed with assembly code. Or, if we are so inclined, we could have an .asm source file that only has directives. A simple example is the below line:
db 0x90
The directive is db. It's not assembly, it is an assembler (nasm) specific thing. the byte is 0x90. This would be assembled just fine as a nop. You don't have to write just 1-byte at a time, there are other directives for varying sizes, here's the list:
db - 1 byte
dw - 2 bytes (double)
dd - 4 bytes (word)
dq - 8 bytes (quad)
dt - 10 bytes (ten)
do - 16 bytes
dy - 32 bytes
dz - 64 bytes
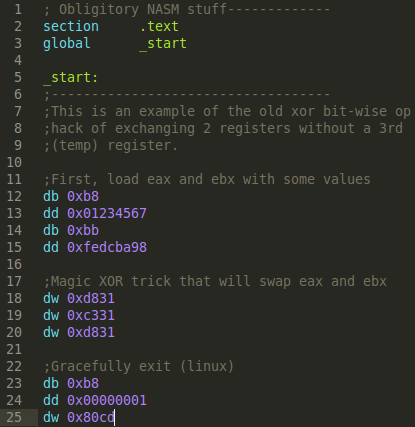
The major upside to this strategy is that you can use standard tools (nasm) to program in machine code. You can also do 64-bit no problem. Personally, the only reason I would use this approach was if I needed to do 64-bit stuff. The downside is the little-endian memory model. In m2elf, I would just state 31d8 for xor eax, ebx. 31 is the opcode for xor, and d8 is the ModR/M byte that specifies registers eax, ebx. This seems very logical, in the context of the order the bytes come in. However, when using the dw directive, it looks like 'dw 0xd831'. This isn't a show stopper so long as you keep it in mind. Just know that any multi-byte directive is going to get reversed. But I still think that this can start to get confusing. For example, when looking at mov eax, 1 in assembly, notice that the debugger shows this as 01000000, meaning the bytes are reversed, but the directive in nasm for 01000000 is 'dd 0x00000001'; so it's kind of like we are double-reversing it. Again, not a big deal, so long as you keep track of this, it may require some trial and error.
Below is what our .asm source file would look like for the xchg trick with only nasm directives:
Then I run:
![]()
And now the 'swap_m' file is executable like the rest of the above examples.
Conclusion:
I know this is maybe a complicated topic, so I hope that the information is as accessible as possible and that I didn't make too many assumptions about the pre-existing knowledge of the reader. Feel free to ask any questions that weren't adequately explained in this post and I will try to make it more explicit. Thanks for reading.