TLDR: /a+/ means "see if there are one or more a's...but not too many"
I find stupid things interesting. I will explain shortly, but I find the below series of commands to be interesting:
Let's take this step by step now. The below screenshot shows me creating a file (file1.txt) with the contents of "baaaaaaaaaab". We then run a perl one-liner to see if the regular expression of a+ has a match in our file (of which it would). The script then prints "match" or "nonmatch" based on this result. We see that it does indeed return "match":
![]()
In this 2nd part, the only thing we do differently with file2.txt is have x's instead of a's. This will insure a non-match:
![]()
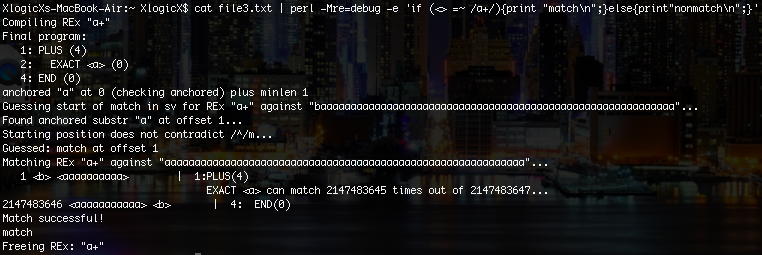
In file3.txt, we go back to having a bunch of a's surrounded by a b on each side, but this time it is a LOT of a's (a little more than 2 billion). I had to separate it into multiple print statements because perl didn't like the x operator with a number as big as I wanted to achieve. As we expect, it still matches, which is logical.
![]()
We now effectively have 3 more a's in our string for file4.txt; as compared to file3.txt. a+ is a way of saying "see if there are one or more a's". We added 3 more a's...but now we don't find a match.
![]()
I find this very cool and interesting, because I'm me, and that's what I do. This isn't a bug. If you want to know exactly why this happens, study an under-the-hood view of a successful match of file3.txt. Look towards the bottom for a larger number and I hope the answer becomes clear.