While the discussion that will follow can all be done exclusively in assembly language, the fun stuff is happening with an understanding of the machine language component. Also, this general obfuscation trick is not completely a new one, it's just my flavor of it.
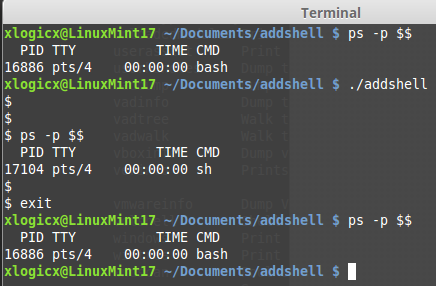
I wrote a program that I called "AddShell". It is very simple; when run, you are in /bin/sh. The below screenshot shows me first checking that I am currently in the bash shell; I run 'ps -p $$' to see what shell I am in. Then I run addshell, we see that we are now in the sh shell. I exit, and we confirm that we are back to bash.
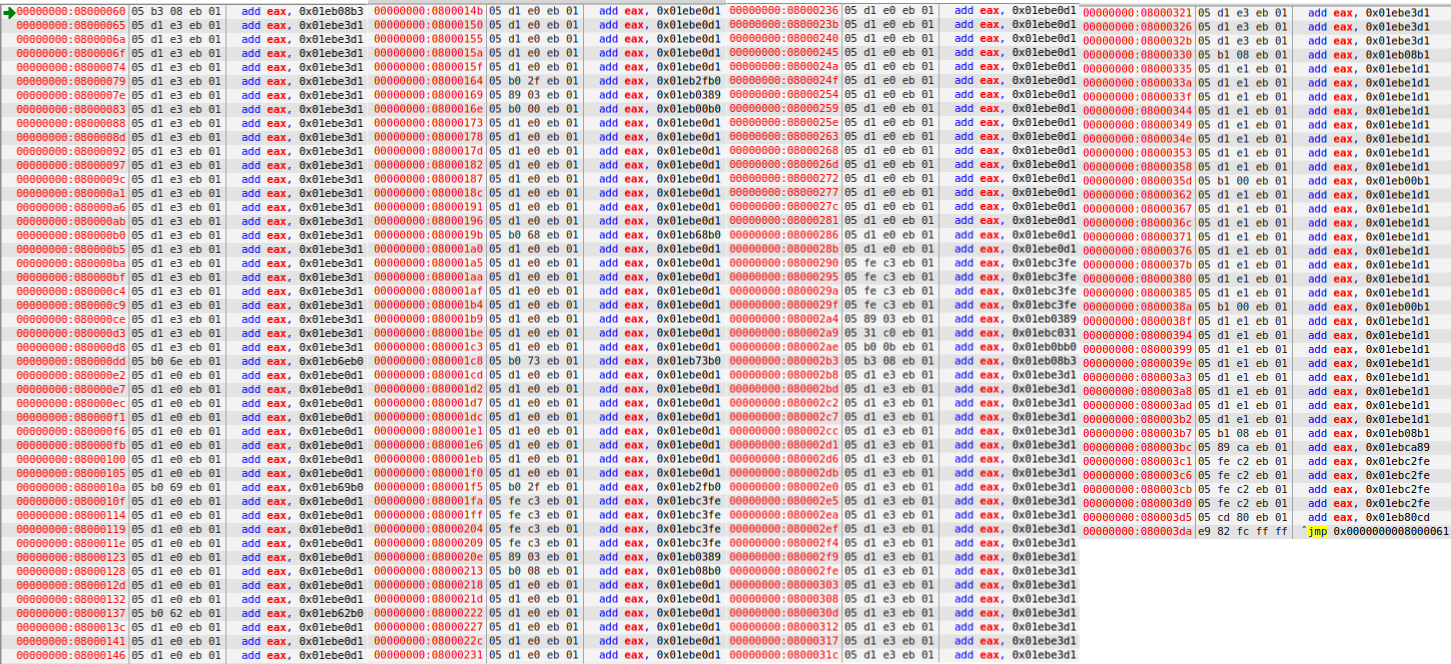
This is what the program looks like from the edb dubugger. Note that it would look just as initially meaningful in other debuggers and disassemblers (ollydb, immunity, IDA Pro, bokken, hopper). As you can see, a bunch of add operations to eax, then finally an unconditional jump. This is the entire program. In machine code, to add an immediate 32-bit value to eax, the op-code is 0x05, then the 4 bytes (32-bit) of data follow. So what you see above with all the ADD instructions is 0x05, and the data we are adding to eax. A couple of hints as to what's going on: If you look closely, our program starts at address 0x...60, and our last jmp instruction is jumping to address 61, even though each of these ADD instructions are 5 bytes long. Also note that the numbers that are being added to eax all end with 0xeb01.
XOR eax, eax (by addition):
I want to show a much simpler example of how this works, before completely diving into the internals of how the above program is pulled off. The concept is very simple, although harder to implement for a not-so-simple program. In our simple example, we exclusive-OR eax with itself (rendering 0 in eax). the machine code for XORing a 32-bit register (or memory address) with another register (register only) is 0x31. The byte that follows 0x31 defines which registers or memory addresses. If it's just 2 registers together, the full instruction is just 2 bytes. If you cared to XOR with a pointer, then the instruction may be longer. This 2nd byte is called the ModR/M byte. In our case, 0xc0 for ModR/M specifies eax for both source and destination operands. So our complete instruction to xor eax with eax is 0x31c0.
The beautiful part of the x86 variable-length CISC instruction set is that you can jump into the middle of a long instruction, and a valid different shorter instruction may be possible, maybe even meaningful. Like our smaller XOR op embedded in a longer (5 byte) ADD op. Let's look at the below program in edb now.
![]()
We see our 0x05 add instruction, but the thing we are adding is interesting; 31c0eb00. Next we jmp to ...61, which would start us at the 31c0 instruction. Here's a screenshot of after that jmp instruction:
![]()
And there we have it, our XOR eax, eax. and the eb 00 part is just jumping to the next instruction, which was our jmp to ...61 again. So we are now in an infinite loop with our XOR and 2 jmps (No ADDs at all).
I will note that our original program above had eb01 endings, instead of eb00. eb00 takes us to the next instruction, eb01 will take us 1 byte into the next instruction. This skips the 0x05 ADD part of the next add and interprets the 2-byte instruction instead, followed by another 2-byte sized jump; allowing us to chain these all together.
You probably get the idea now, but this section is for those that wants to see the details of how the original code above comes to be. The main strategy is to take whatever program we want, and to translate it into 2 byte instructions. I have a simple assembly program that just makes use of the sys_execve linux syscall:
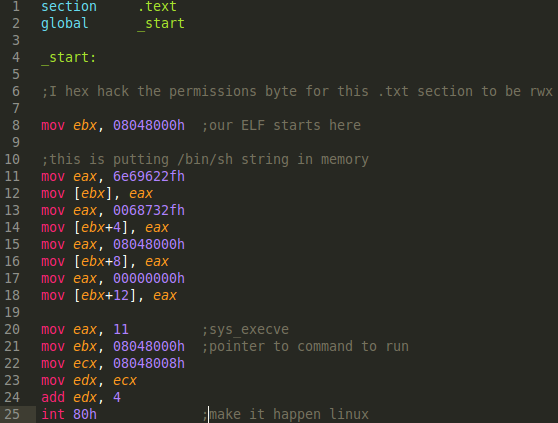
The main problem is that many of these instructions are far more than 2 bytes. Fortunately, fairly simple tricks can be used here. For example, MOVing a 32-bit immediate to ebx is fairly long. But, we can MOV 1 byte to the bl register (lowest byte of 4 byte ebx register). We can then left shift that byte (we also have a 2 byte instruction option for this) to where it needs to be. We strategically do this with all 4 bytes of ebx. Also, instead of an ADD instruction, we do have a 2 byte INC instruction, to increment however many times we would have added. There's a 1-byte version of INC as well, but I opted for the 2 byte version to be a purist with the format of this. Below is a machine code source file of where I went with this:
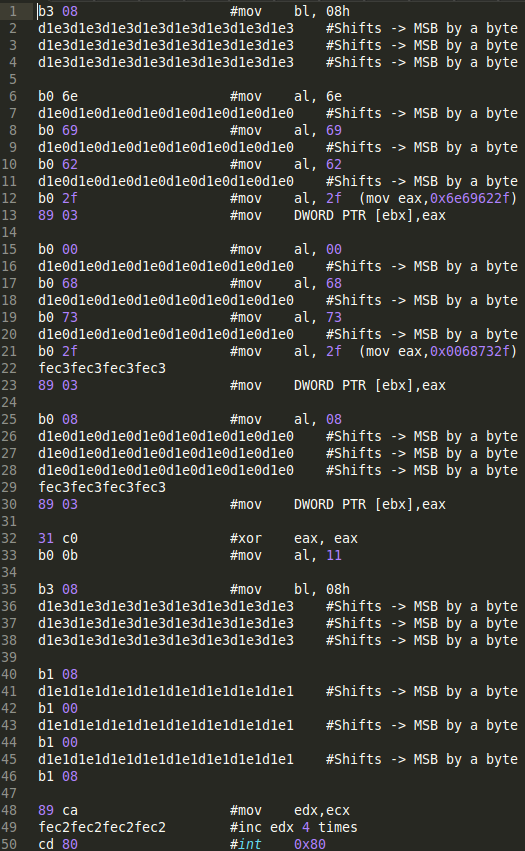
This is not just arbitrary notes; this file is completely valid as an input to my m2elf script (running it will produce the program we are talking about). One major difference is that I use 0x08000000 as an ELF start instead of 0x08048000. Nasm decided the latter, m2elf consistently starts at 0x08000000; so you can actually plan for it. long chains of d1e3's are just 2-byte SHL instructions that I jammed together for 'readability,' but they are still just 2 byte instructions. Same goes for what I did with the chained fec3 like blobs.
All of these 2 byte instructions are now the first 2 bytes of the 4 byte operand for our add instructions, where our last 2 bytes are the jump to the next 2 byte instruction (within the ADD).
So, the first pass of the program (until the JMP) is just a bunch of adding to eax. After the JMP, we fall down the chain of 2 byte instructions like the ADDs were never there, and the eb01 jmp (to 'next' instruction) is the glue that holds them together.
I have also included the addshell program for those who want to try running or debugging this themselves.