This article is about a redundancy with short and near jumps. Both of the jumps I will talk about are relative; the immediate data after the jump instruction is a signed offset for how far to jump. The difference between a short and near jump is simple: the 0xeb short jump has a byte for its operand, and the 0xe9 near jump has 4 bytes for it's operand. This means that we can jump -128 through 127 bytes with a short jump and -2,147,483,648 through 2,147,483,647 bytes with a near jump.
First of all, the assembler I use (nasm) will try and guess which type of jump to use if you don't specify short or near. So if I'm jumping farther than 128 bytes, it will use a near jump for me, and if less than that, a short jump. At a low level, I find this interesting; that the same assembly instruction can have different machine code depending on how far away (in bytes) the label operand is. Of course, different machine code for consistent assembly isn't weird in general, an addressing mode can quickly change which machine code to use. I still find this behavior for the jump instruction interesting though.
Say we we're only jumping forward 127 bytes, but for some reason we wanted to use the near jump (0xe9) format. By default, nasm would use a short (0xeb) jump. The short jump range is still a valid range in near jumps (speaking for machine-code encoding). Fortunately, we don't need to do machine code hacks in order to over-ride this; nasm allows us to use 'short' and 'near' arguments to the jmp instruction (to over-ride the default).
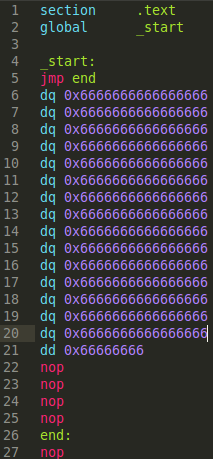
Here is a source file. the jmp jumps to a label 128 bytes forward, which will require a near jump.
Here is a debugger screenshot of the machine-code used for the 'jmp.'
![]()
Now let's move our 'end:' label by 1-byte back (to jump 127 bytes, of which a short jump can do):
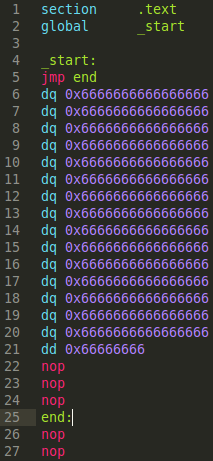
Here's the debugger output:
![]()
So let's over-ride this short jump (we still only want to jump 127 bytes, but with the long 4-byte operand encoding of a near jump):
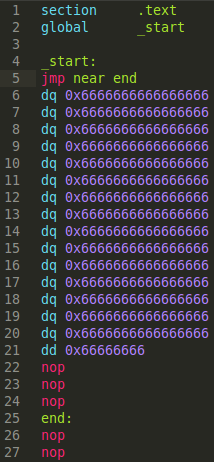
And our result (in debugger):
![]()