I'm finding that there is a full playground in the ModR/M encoding, and this post is specifically about a SIB obscurity, only because of the way I see NASM assembling some of my assembly. Then I found other cool things NASM puts up with
Consider this code:
![]()
Functionally, they both result in the same thing. There is even seperate machine-code to accurately represent both (kind of). But if we assemble it, we end up with this:
![]()
Even though we can hand code the machine code to get this:
![]()
The SIB byte allows us to do complex memory/pointer syntax of [Base + Index*Scale + Displacement], where the Base is a general purpose register, Index is another general purpose register multiplied by 1, 2, 4, or 8 (the Scale), and the Displacement is an immediate value. Becuase of the exceptions found in the encoding table for the SIB byte, any one of the Base/Index/Displacement are optional. You can choose not to have an Displacement, which is actually defined in the ModR/M, not the SIB. You can not have an Index (see chart 1), because "none" is an option that takes over the option of ESP. You can also not have a Base (see chart 2), which is a special case that takes over the option of EBP, although this comes with a side-effect of having an offset (if none was selected with ModR/M).
(Chart 1, No Index, Click to enlarge):
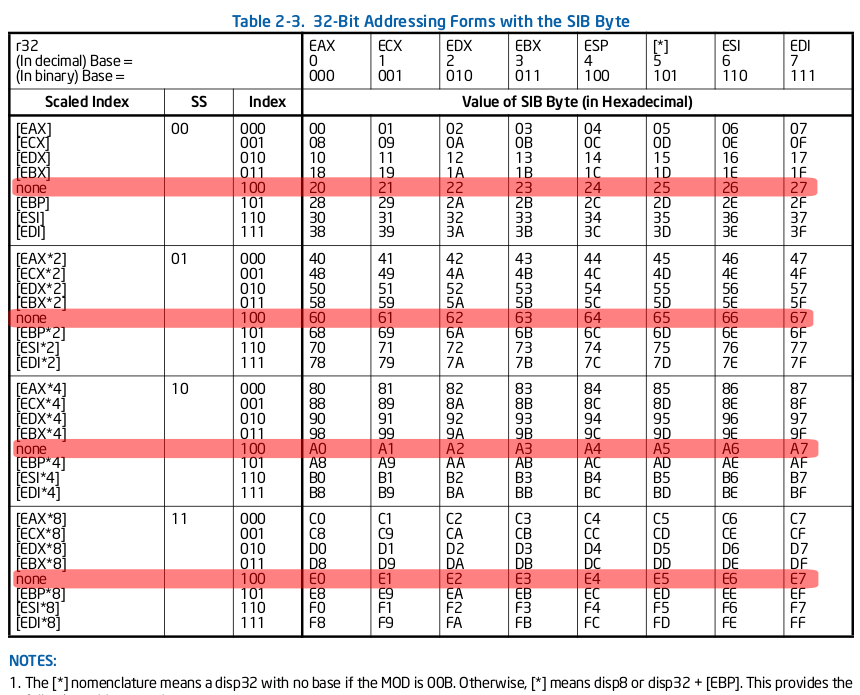
(Chart 2, No Scale, Click to enlarge):
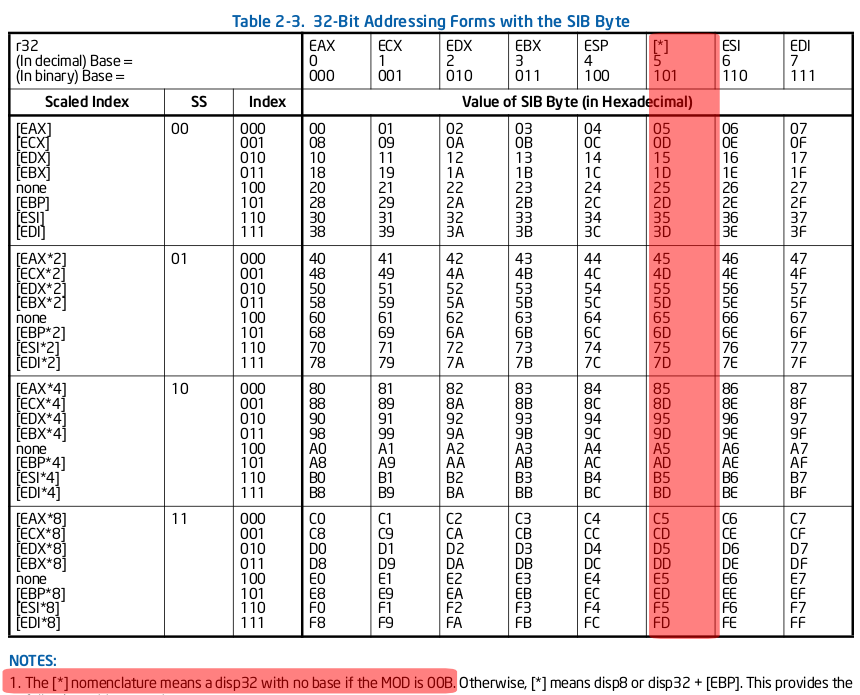
That means that 'xor eax, [eax * 2]' isn't exactly a thing that exists. Because we are using the Index and no Base, we happen to be using that special case that requires an offset. So this is more accurately 'xor eax, [eax * 2 + 0x00000000]'. It carries the same meaning, since we aren't arithmetically adding anything extra. But instead of interpretting 'xor eax, [eax * 2]' like I just did, nasm does 'xor eax, [eax + eax]'. This interpretation uses eax as the Base, and eax * 1 as the Index * Scale; this doesn't require an Offset.
Now, if I said 'xor eax, [eax + eax * 2]', it would dutifully use my 'eax * 2' Scale.
So there are at least 2 ways to represent [eax * 2]-ish. Nasm picks [eax + eax] because:

(from section 3.3 of the NASM manual)
Is it better? It depends on how you look at it. It is better for smaller machine code, as in 'xor eax, eax' has shorter machine code than mov eax, 0 (but effectively has the same result). 'xor eax, [eax * 2 + 0x00000000]' takes more machine code. But then I bench-marked the two versions...
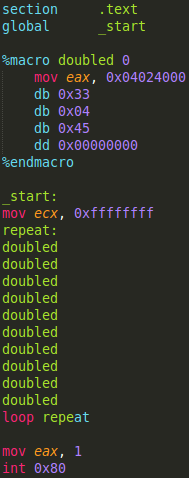
Testing on a 32-bit system, the xor eax, [eax * 2 + 0x00000000] form (the one with MORE machine code) tested consistently quicker (and I took a lot of samples). On my 64-bit system, the results were inconsistent; they both took about the same time but varied in which was the quickest.
It's worth noting that you don't have to do any machine code hacking to use the faster (on some systems) version of this, just make sure to include the zero offset (xor eax, [eax * 2 + 0]), or you can even use a nasm feature to over-ride this choice: 'xor eax, [nosplit eax * 2]. And if you assemble my source files and wonder why they seg-fault, you have to hack the permissions of the .text section. It's actually easier than it sounds, just use a hex editor (I like vbindiff) and change the first 0x05 you see to a 0x07.
As a final word on how awesome NASM is, you can do some super ignorant memory addresses, but so long as it is somehow equivilant to something valid, NASM will make attempts. For example, a scale of 5 or even subtraction! Consider:
![]()
NASM assembles it to:
![]()