
This is referring to my previous post Vm0wd2Qy, and a clarification of how I got my results. If you repeatedly Base64 encode a string, you will eventually get Vm0wd2Qy as the first part of your string. In my previous post, I have 10,000 characters that you would eventually get as the first part of your string if you keep doing this. My process for getting these 10,000 characters involved a kind of brute force, but with the obvious assistance of scripting and cli stuff.
Lets just get Vm0 part of Vm0wd2Qy real quick, form a starting string of 'lol'. We do this by encoding 'lol', then encoding the result of that, and repeating:
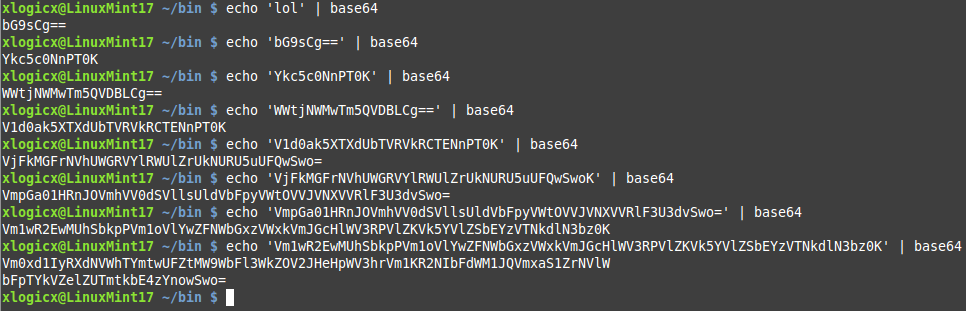
In our last result, we do see 'Vm0'; we see our magic string starting to form. But as far as brute forcing this goes, I hope you see the problem: how do we know where the magic string ends, and where all of this extra baggage starts? Let's also consider another example of making 8 base64 passes with a different starting 'seed' than 'lol'.
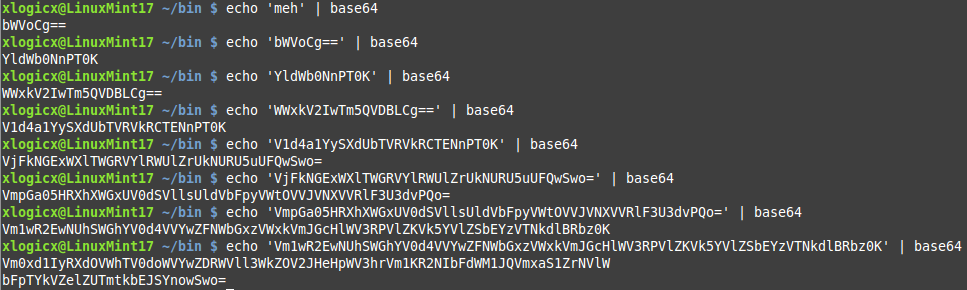
If you just look at the beginning and end of the final strings from each seed, it looks like they end up being exactly the same. But a closer looks shows that this is not so:
Vm0xd1IyRXdOVWhTV0doWVYwZDRWVll3WkZOV2JHeHpWV3hrVm1KR2NIbFdWM1JQVmxaS1ZrNVlWbFpTYkVZelZUTmtkbEJSYnowSwo=
Vm0xd1IyRXdNVWhTYmtwUFZtMW9WbFl3WkZOV2JHeHpWV3hrVm1KR2NIbFdWM1JQVmxaS1ZrNVlWbFpTYkVZelZUTmtkbE4zYnowSwo=
It looks like they both start with "Vm0xd1IyRXd," But that doesn't mean "Vm0xd1IyRXd" is the magic string. If only it were that easy.
Instead of working smart though, I worked brute. The scripted idea was to run the string through many passes, with all possible 1 character seeds (64 of them), only output the first 'x' characters, and hope for 'uniq -c' on the result to only return one value. I used all seeds to hopefully avoid the above problem of having non-unique yet invalid magic string properties (no promises that this guarantees the right result, however, just a best effort).
Here's an example of the script I was working with:
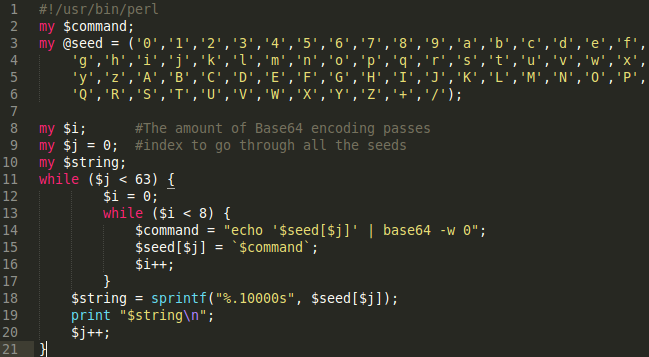
When run, here's a screenshot of the tail end of the output:
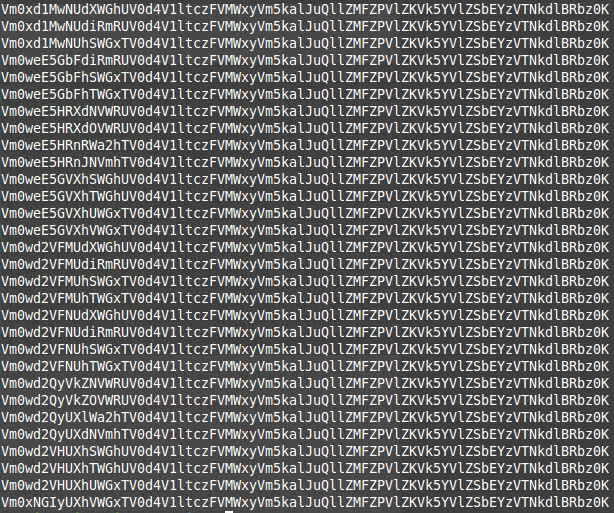
the uniq command would indeed give me one entry for each line (not what I want). Here's the output I would get from uniq if I changed sprint("%.10000s".... to sprintf("%.3s"... (this line is the 'x' characters cutoff piece).
![]()
This is the kind of output that I'm looking for.
If I want to get a large (over 9000) string, I need to set the sprintf value to truncate at the goal value of %.9000s (I went for 10000). if uniq doesn't come back with just 1 result, then I need to ramp up my $i variable (this variable defines how many base64 passes to make for each starting seed). On the flip side, if I preferred not to make any more base64 passes and just wanted to know how many non-unique characters I had for all 64 strings, I could bring the sprintf number down until uniq -c gave just one result.
There is a limit to how high you can set $i though; your shell would eventually throw a fit. Actually, without 'use warnings;', you would just get the wrong result. Otherwise, you would get something like "Can't exec "/bin/sh": Argument list too long at base64.pl line..." with a value of $i being too high. Because of this limit, I wasn't able to get much higher than 10,000 non-unique characters in my string without having to do something like recompile the kernel. I forget how high I made $i, but it was one number less than what would give me an error.